The multi-billion dollar industry of music attributes nearly two-thirds of its global revenue to streaming. Utilizing Spotify's open API and top chart datasets, this diagnostic analysis aims to identify which, if any, trends and characteristics lead a song's to success. The two criteria song success were accounted for were total streams and the number of times the song would reach the top of the Top 200 chart.
One key finding is that while distribution shows top songs typically are high in danceability, energy, and loudness; there is little evidence that suggests any of the audio characteristics tend towards higher total streams within the top charts. Another key finding is that timing plays an important role in top chart placement, as even songs with significantly fewer total streams can dominate the top chart.
A potential improvement on the analysis would be to incorporate a randomized set of songs with selection past just the top chart. Expanding the dataset past the top charts may lead to stronger trends which were not apparent here.
Every year 22 million new songs are released onto Spotify, with a mere 1,500 of them ever reaching the Top 200 chart. Using this kaggle dataset, which documents the Top 200 and Viral 50 charts from 2017 to 2021, hopefully insight can be offered about what trends and features lead to a song's success.
To identify which trends and aspects lead to a track's success, first the tracks of interest need to be queried from the 26 million row dataset. In this analysis, the two metrics of success that will be used are the total number of streams a track gets and the number of times it places the number 1 spot on the Top 200 chart.
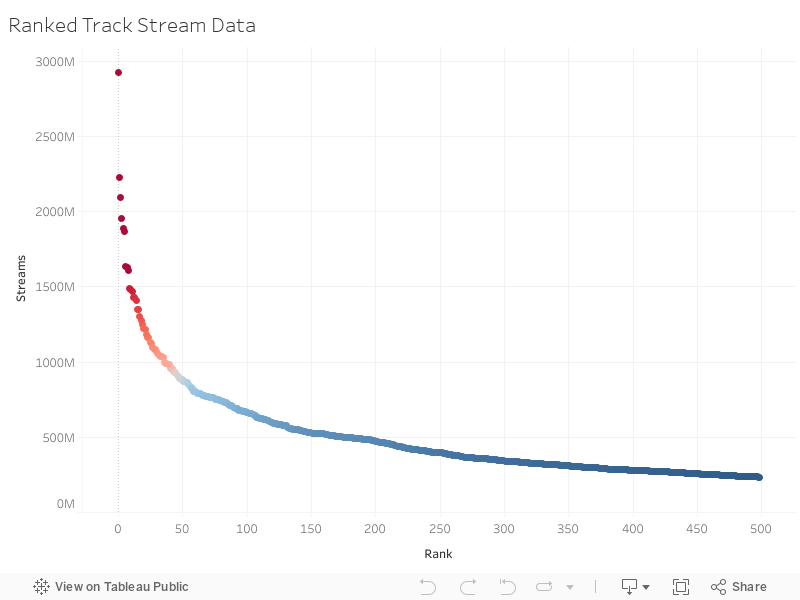
Query 1: Top 500 Globally Streamed Tracks
select title,url,sum(streams) as num_streams
from spotify_data
where region = 'Global' and chart != 'viral50'
group by title, url
order by num_streams desc
limit 500
After obtaining the highest streamed tracks, the audio features can be obtained using Python and Spotify's own API. The API can be used to obtain a track's tempo, danceability, and energy among other features, all of which may show trends in the top stream data. To do this, a short script is used to run through the queried data and retrieve the analyses from Spotify's API.
Python 1: Retrieve Track Features From Spotify API
import pandas as pd
import re
import requests
# read csv
df = pd.read_csv('top_500_streamcounts.csv').to_string()
# Extract song ids and clear
matches = re.findall(r"track/(.+) ",df)
matches = list(map(str.strip,matches))
# Extract streams and convert to int
streams = re.findall(r" ([0-9]{8,13})",df)
streams = list(map(int,streams))
# Get access token
auth = requests.post('https://accounts.spotify.com/api/token', {
'grant_type': 'client_credentials',
'client_id': 'hidden',
'client_secret': 'hidden',
})
access_token = auth.json()
access_token = access_token['access_token']
# Create access token header
header = {'Authorization': f'Bearer {access_token}'}
# Grab audio features
link = 'https://api.spotify.com/v1'
final_df = {'name':[],'streams':streams,'duration_s':[],'danceability':[],'energy':[],'loudness':[],'speechiness':[],'tempo':[],'valence':[]}
for song_id in matches:
# Get name, duration_ms and append to dataframe
track = requests.get(f'{link}/tracks/{song_id}',headers = header)
final_df['name'].append(track.json()['name'])
final_df['duration_s'].append(int(track.json()['duration_ms'])/1000)
# Get track analysis values
track_features = ['danceability','energy','loudness','speechiness','tempo','valence']
features = requests.get(f'{link}/audio-features/{song_id}',headers = header)
for feature in track_features:
final_df[feature].append(features.json()[feature])
final_df = pd.DataFrame(final_df)
final_df.to_csv('Projects/Spotify/features.csv')
Python 2: Create Histograms For Track Features
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv('/Projects/Spotify/features.csv')
fig, axs = plt.subplots(3,3,tight_layout=True)
fig.suptitle('Audio Analysis Histograms',fontweight='bold')
axs[0,0].hist(df['danceability'],bins=25,color='limegreen')
axs[0,0].set_ylabel('Count')
axs[0,0].set_title('Danceability')
axs[0,1].hist(df['energy'],bins=25,color='orangered')
axs[0,1].set_title('Energy')
...
plt.show()

The histograms shown above visualize the distribution of the audio features for the 500 songs. Some points from inspection are that the majority of songs are generally high in danceability, energy, and loudness, and generally low in speechiness. The distribution for tempo and valence seem to be more evenly distributed across the spectrum. Next to see how each audio feature affects total streams, they'll be plotted against each other to visualize any trends.
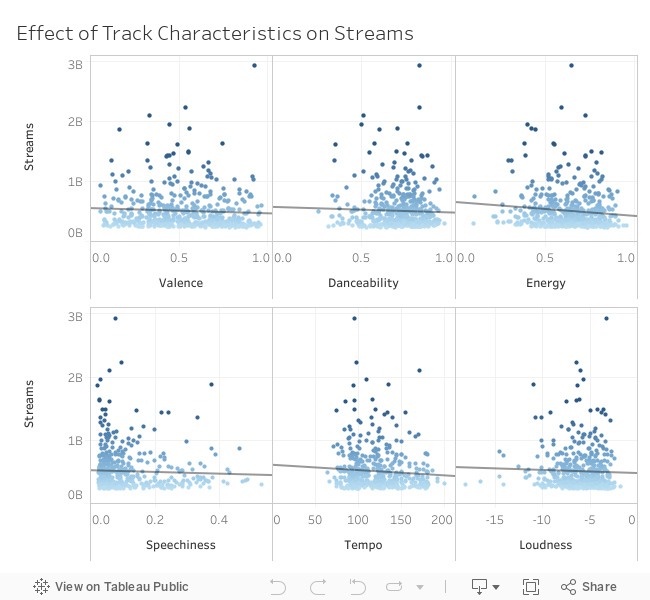
The plots show that there is little to no correlation between the track's individual audio features and their streams. While it could be true that audio characteristics have little effect on total streams, potential bias in this dataset may be the cause of a lack of trends. Since the data is limited to songs which have made it into the Global Top 200 chart, expanding the dataset outside the top chart and using random selection may show a more clear trend.
Aside from streams, the second metric for measuring success used in this analysis is how many times a song could maintain the top spot on the Top 200 chart. One general assumption would be that songs with more streams would typically have a higher number of placements, but first we'll check this assumption by visualizing the data with a count vs streams plot.
Query 2: Number Of Top Spot Occurrences
select first_place.title,
first_place.num_first_places,
all_cond.streams
from (select title,
count(title) as num_first_places
from spotify_data
where "rank"=1 and region = 'Global' and chart = 'top200'
group by spotify_data.title
order by num_first_places desc) as first_place
inner join (select title,sum(streams) as streams
from spotify_data
where region = 'Global'
group by spotify_data.title) as all_cond
on first_place.title = all_cond.title
order by num_first_places desc
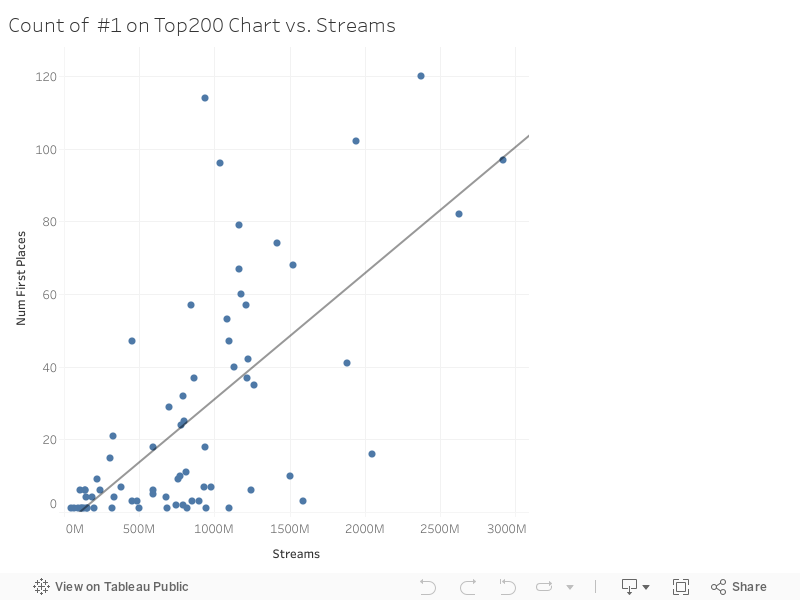
The trend validates the assumption that generally songs with higher streams top the Top 200 chart more often. However, some interesting datapoints become more apparent in the plot with further inspection such as the songs rockstar and Circles. Both songs are from artist Post Malone with rockstar having been streamed 935 million times within this time period and placing first 114 times, and Circles being streamed nearly 1.6 billion times and placing first 3 times. So this poses an interesting question: Why did a song with close to half as many streams maintain its top spot nearly 40 times longer? To answer this question, we'll need to take a look at the timeline for the top spot.
Query 3: Top Spot Timeline
select title, "date", streams
from spotify_data
where "rank" = 1 and region = 'Global' and chart != 'viral50'
order by "date" asc


The above visualizations show a timeline of which tracks held the top chart spot, along with their respective streams, around the time that rockstar and Circles held it. As seen from the visualizations, Circles was released into a time with much tougher competition, while rockstar was uncontested, aside from the annual resurgence of Mariah Carey's "All I Want for Christmas Is You", and narrowly missed other chart toppers. It appears then, that a significant factor in a songs success is its release and timing.
Data shows that generally the top performing songs (in terms of total streams) are high in danceability, energy, and loudness, and low in speechiness. While these songs tend towards these characteristics, there is little evidence that the characteristics have any correlation with the total number of streams a track receives. Possible improvements towards further investigating this conclusion would include expanding the dataset past the Top 200 chart songs and implementing a random set to control for bias. Songs that receive higher total streams will also tend to maintain the top chart spot for longer, but ultimately will depend on timing with other major songs.